Previous topic |
Ada Home Page |
Index
File of lines of characters
When you need to process every character in a file, and you are also
concerned about line boundaries, your code will always fit the following
pattern:
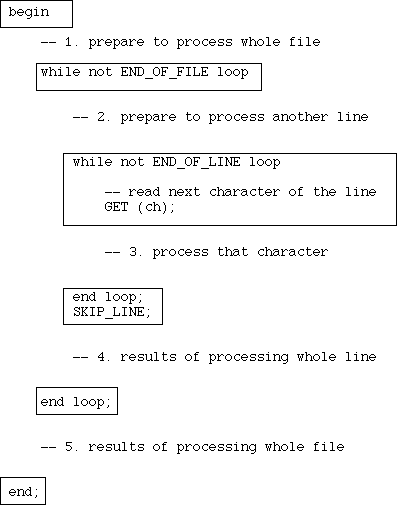
Note the loop structure:
- the outer loop processes one line at a time
- the inner loop processes each character on the line in turn
- the SKIP_LINE after the inner loop is crucial. Without it, the outer loop
never progresses beyond the first line, and loops forever
(can you work out why?)
Using the template
You can use the above template to write your file processing code:
- Decide what (if anything) needs to be done before any of the file is read.
- Write statements for it, and plug them in at point 1 in the template.
- Decide what (if anything) needs to be done before you start to read a new
line.
- Write statements for it, and plug them in at point 2 in the template.
- Decide what needs to be done to process a character that has been read in.
- Write statements for it, and plug them in at point 3 in the template.
- Decide what final processing needs to be done (if anything) when the end
of a line is reached.
- Write statements for it, and plug them in at point 4 in the template.
- Decide what final processing needs to be done (if anything)
once the end of data is reached.
- Write statements for it, and plug them in at point 5 in the template.
Examples
The previous example program
which copies one file to another runs a small risk. It reads a whole line
at a time, assuming the maximum length of any line is 200 characters. Any
line that is longer than 200 characters will be truncated.
That problem can be overcome by copying each character individually.
An example shows how.
Another example program
tabulates the frequency of occurrence of each different letter in a file
of text.
Previous topic |
Ada Home Page |
Index
c-lokan@adfa.oz.au / 23 Feb 96